Cliosight Templates
Data Engineering
Proficiency Level: Advanced / Cost: $0 per month
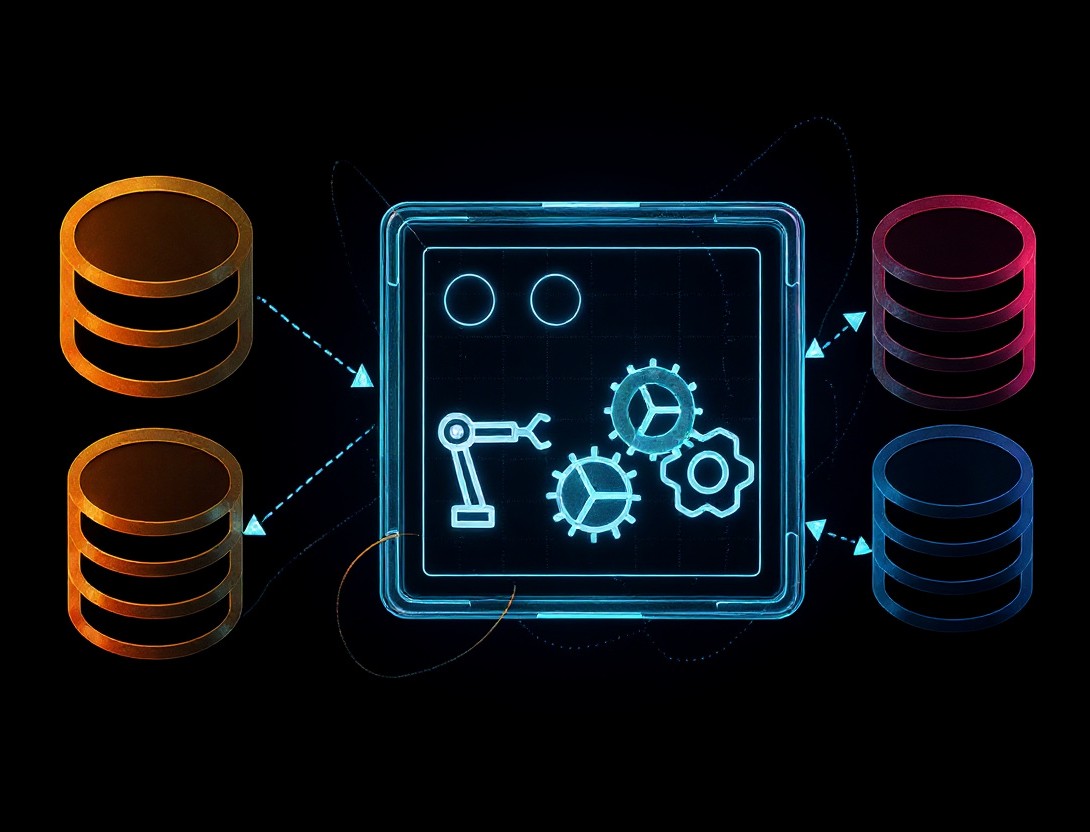

Data Migration Pipeline
Most companies use tools like Informatica, Portable, Dell Boomi, Talend and data clean rooms to work on volumes of data. This is done for various reasons that are strategically important for the organization, like migration from one service to another. We understand that this is a critical task for any company irrespective of their size, stage and skill level.
In this project we will focus mostly on automation configs. We will see how data pre-processsing tasks like splitting, cleaning and merging can also be done in an external project that uses scripting languages like Python. To support these types of collaborative data management tasks, we will use the report data of an intermediate dataset that is created by using in-built datasources before pushing into the destination datasource.
Data analysis is inherently multi-step. Often, teams must transfer data across
databases—sometimes preserving its structure,
other times transforming it along the way. These sources may reside in the cloud or
on-premise, adding further complexity.
To streamline such operations, an intuitive and efficient interface is essential.
Furthermore, data science professionals typically export processed datasets as .csv files,
including test data,
which is often shared in the same manner. These files are saved locally or on virtual
machines.
They may also reside in cloud storage environments linked to serverless infrastructure where
tools like Jupyter are
remotely accessed. In addition to leveraging large public datasets available online,
practitioners can register and
share their own public or private datasets using built-in libraries provided by TensorFlow and
PyTorch. These libraries however impose a steep learning curve due to framework-specific boilerplate apart from rigid formatting requirements making it complex for beginners.
With Cliosight, users can orchestrate a sequence of data operations—either serially or in
parallel—to achieve targeted data quality and
analytical outcomes. For example, data can be ingested into an embedded database for real-time
visualization on dashboards,
or routed through external processing pipelines for validation and enrichment prior to
migration into a cloud-native datastore.
Reports in Cliosight can be used for sharing datasets. They can be updated in an external
application's code to be written back as a
new report or as additional rows in an existing report. The major advantages of this approach
is that, users can conviniently share
multimodal datasets in a collaborative work environment with diverse technical skills.
Also, by applying role-based access control, actions on that data can be restricted by the
resource owners.
Primary Features
- Integrating storage services
- Cliosight API in Python
- Database backup
- TensorFlow and Pytorch Libraries
- Configuring a data pipeline
- Project Portability